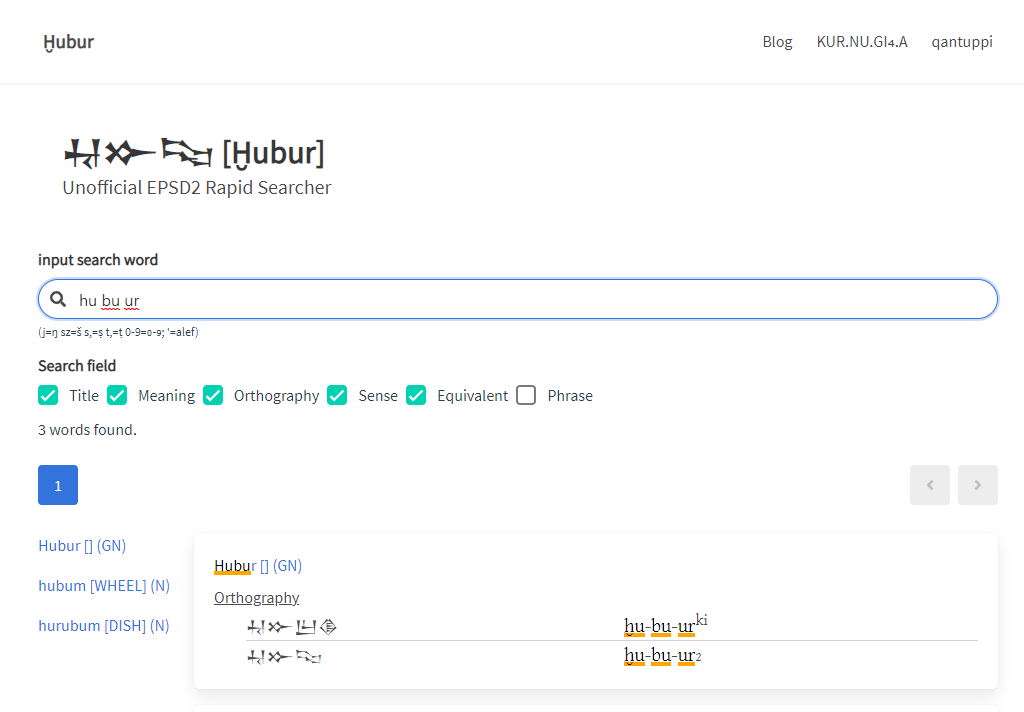
# Ḫubur[フブル]
2021/02/11にフブルというWebアプリをリリースしました。ePSD2というシュメール語のオンライン辞書サイトを検索するアプリです。
https://hubur.kurnugia.com (opens new window)
これはソースコードも公開していて、こちらにあります。
https://github.com/uyumyuuy/hubur (opens new window)
# ePSD2とは
米ペンシルバニア大学考古学人類学博物館(Penn Museum)が運営しているシュメール語オンライン辞書プロジェクトです。
http://oracc.museum.upenn.edu/epsd2/index.html (opens new window)
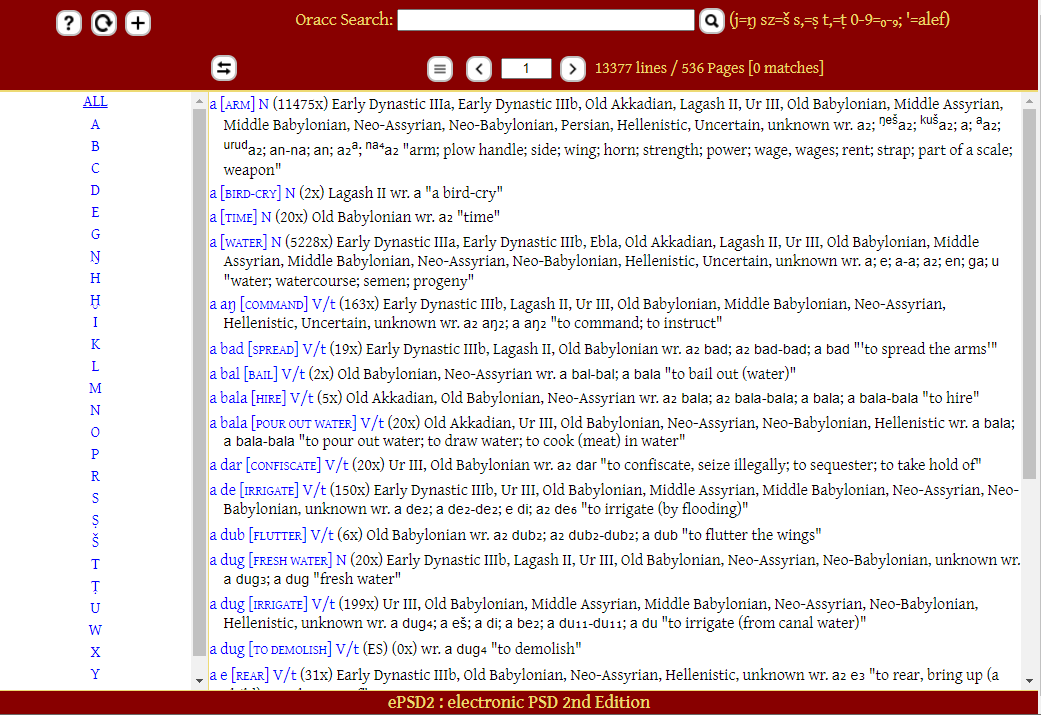
もともと1974年に編纂開始されたPSD(Pennsylvania Sumerian Dictionary)という紙の辞書があって、2004年にそれを電子化したePSDというサイトが作られたのですが、それを大きく情報量を増やしてリニューアルしたのがePSD2というわけです。
日本の研究者では中央大学の唐橋文先生が関わってらしたみたいですね。(記事 (opens new window) )
ディレクターはスティーブ・ティニー博士で、この方はユニコードへの楔形文字の収録にも中心的な役割を果たした、私の中では超超有名人なんですがそれはさておき。
# 改善したい点
そういうePSD2なんですけど、なんというかちょっと、検索が使いづらい……。
例えばこんな感じ。
検索結果の表示順
ePSD2の検索では、検索キーワードで全検索した後、語をアルファベット順に並べて表示するというアルゴリズムになっているみたいなのです。
なので例えばginみたいな頻出語で検索をかけると、703語、29ページ分の検索結果がa[ARM]Nから順番に表示されます。ginという語が表示されるのは9ページ目です。
画面拡大時の誤タップ
スマホで検索結果を見ているときに画面を拡大してから項目名をタップすると隣の語のページに飛んでしまうという謎の挙動があります。
javascriptによる遷移
上の項目の原因でもあるのではと思うのですが、ePSD2では検索結果から単語ページへの遷移をjavascriptのクリックイベントでフォームにPOSTする形で設計されています。
このため、「新しいタブで開く」などのブラウザの機能が動作しません。また、ブラウザに表示されるURLが常に固定のため、単語に対するブックマークやリンクが難しいです。なお単語ページの最下部に表示されているCitation URLという文字列がパーマリンク用のURLになっています。
さて、こういったわけで、便利なんだけどやや使いづらく感じていたわけです。ePSD2はかなり活発に開発が進んでいて、およそ半年ごとにバージョンアップされています。検索機能についてもすぐなんとかなるだろうと思っていたのですが、データの更新に比べると進展がなく、これは検索インタフェースだけ自分で作った方が便利になるんじゃないかな……と思ったのでした。
# データの取得と著作権法
検索機能をつくるためには検索元のデータを手元に入手する必要があります。また検索結果には元データのうち検索にヒットした箇所を表示したいですよね。
他者の著作物をコピーして自分のサイトで公開するわけですから、通常は著作物の公衆送信権に配慮する必要があります。日本の著作権法では平成21年度の改正により『送信可能化された情報の送信元識別符号の検索等のための複製等』(著作権法47条の6)という例外規定があり、検索エンジンによる複製と再配信を合法化しているわけですが、この例外規定を満たすためにはいくつかの条件があります。詳しくは省略しますがフリーハンドでの利用はできないわけです。
ですが、ePSD2の場合は掲載されているデータの加工と再配信が著作権者(つまりThe Sumerian Dictionary Project)により明示的に許諾されているため、ライセンスに従って自由に利用することができます。
ePSD2の個別ページにはライセンスの記載がないのですが、ePSD2のトップにはフッターに「CC BY-SA The Pennsylvania Sumerian Dictionary Project, 2017-」と記載されています。
ePSD2が属する親プロジェクトOraccにはHow to reuse material from Oracc (opens new window)という記事があり、
Oraccのデフォルトのライセンスはここ (opens new window)で説明されるCreative Commons Attribution Share-Alikeライセンスです。このライセンスに従う限り、Oraccの素材を再利用する際に許可を得る必要はありません。(私訳)
原文
The Oracc default license is the Creative Commons Attribution Share-Alike license, described here (opens new window). If you abide by this license you do not need to ask permission for reusing Oracc material.
著作権やライセンスの詳細は、関連するページのフッターに記載されています。各プロジェクトには、明確な言葉で書かれたライセンス条件へのリンクがあります。(私訳)
原文
You should be able to find details of copyright or licensing in the footer of the relevant page. Each project should also have a prominent link to its licensing terms, written in clear language.
と書かれています。
ePSD2のデータはCC BY-SA (opens new window)のライセンスに従って利用できると考えてよさそうです。CC BY-SAというのは『クリエイティブコモンズ 表示・継承』と訳されるもので、簡単に言えば原著作者の表記を行い、二次著作物も同じ条件で他者に提供するのなら自由に改変・配布・販売してもよいというものです。まったく問題ないですね。なお本記事自体も同様にCC BY-SAライセンスです。
# スクレイピング
そういうわけでePSD2のデータを手に入れましょう。ePSD2プロジェクトではなんらかの構造化されたデータ形式で扱われていると思うのですが、生データの配布はされていないようなのでWebページからリンクを辿って収集することにします。
Webサイトからデータを収集することをスクレイピングといいます。今回はPythonという言語のScrapy (opens new window)というライブラリを使ってスクレイピングすることにしました。Pythonはもう10年以上使ってすっかり他に馴染んでいるお気に入りの言語です。Scrapyを使うのは初めてでしたが、日本語のチュートリアル (opens new window)が充実していて簡単に使えました。
スクレイピングでは個別のページをひとつずつアクセスしてページに記載されている情報を収集するわけですが、何も考えずにプログラムから連続でアクセスするとサーバーに多大な負荷を与えます。
Scrapyのデフォルトの設定はわりと強気で、1ドメインあたりの並列数は8、ダウンロードごとの待機時間はなしになっています。さすがにこれは良くない。1秒に1回くらいのリクエスト数が紳士的と言われたりもします[1]。今回はリクエストごとに10秒の待機時間を設けることにしました。だいたい6000件くらいのデータ数なので、土曜日に始めれば日曜には取得が終わります。その間に残りの開発を進めようという計画でした。
とはいえ日本においてはその水準のアクセス頻度でも攻撃とみなされて逮捕に至った例 (opens new window)もあります。
# 検索機能
Webアプリで検索機能をどのように実現するかについて、当初はローカル検索でいいかと思っていました。 全データをダウンロードさせ、フロントエンド(ユーザのブラウザ環境)で検索を行うというものです。私たちのサイトで言えばqantuppi (opens new window)やクルヌギア (opens new window)での楔形文字の検索はこの方法になります。データ量が限られていて、特に秘密にしないといけない内容もなければこれが一番お手軽で検索スピードも速くていいですね。ただし今回はこれまでのサイトよりもデータ量が多いので、きちんとインデックスを作って検索しないとうまくいかなそうです。
javascriptでデータの全文検索をするライブラリを探してみるとFlexSearch.js (opens new window)というのが見つかりました。なんだかすごく高速な感じをアピールしていて、それでいて使い方がシンプルでなかなかよさそうです。
スクレイピング途中のデータを使って試作してみたところでは使い勝手もよく機能も十分だったのですが、予定の1/3ほどのデータ量の時点で、検索データのインデックスが10MBを超えてしまいました。
インデックスのダウンロードさえしてしまえば、検索自体はブラウザでもさくさくできるのですが、さすがにこのデータ量はWebアプリとしては現実的ではありません。残念ながらひとまずはローカル検索を諦め、サーバサイドでの検索に切り替えなくてはならないようです。
ここはサーバレスファンクションの出番でしょう。サーバレスファンクションというのはプログラムコードを小さな機能単位で登録・実行できる仕組みで、サーバの管理運用はまったく意識しなくてもサービス側でよしなにやってくれるというものです。
今回は、最初に作ったものから、与えられたワードで検索した結果を返す機能のところを切り出して使うことにしました。
サーバレスファンクションを提供する企業はいろいろあるのですが、vercelにお願いすることにしました。vercelはWebサイトのホスティングサービスですがapiディレクトリにソースコードを置いておくと勝手にサーバレスファンクション化してくれるというスーパーお手軽なソリューションです。しかも個人・非営利のサイトではサーバレスファンクションも含め完全無料で利用できるのでとっても嬉しいぞ。
# 検索インデックスの作成
今回作るようなデータ検索と表示機能がメインのアプリでは、データをどのように構造化してどんなインデックスを作るかという点が設計の大事なところです。
たとえばNINDA (opens new window)(パン)みたいな語がだと、楔形文字の綴りが5種類、意味が2種類、フレーズデータがすごくたくさん登録されています。このページの中でどの部分を取り出して検索対象にするかを考えていきます。「((OB Nippur Aa 210:1; OB Nippur Ea 210)」みたいな出典の情報は検索にひっかからなくてもいいかな……。あとninda duとninda galみたいな熟語があるのですが、だからって「du gal」みたいな検索語でnindaの語が結果に出てくることは期待されないでしょう。


そういうわけで、検索対象はページの中の楔形文字の綴り、翻字、訳語とした上で、小項目ごとにインデックスすることにします。
FlexSearch.jsだと検索内容の語分割(split))や文字の同一視(encode)をいろいろカスタマイズできるようになっています。というか英語でなければその辺の考慮が必須なんじゃないかな。
たとえば語分割のデフォルトは/\W+/なんですね。んでjavascriptの正規表現での\Wの定義って[^A-Za-z0-9_]なんです。ということはどういうことかというと、例えばšakanka gin₆-na = ma-ḫi-rum ki₂-nuみたいなのを分割すると、
console.log("šakanka gin₆-na = ma-ḫi-rum ki₂-nu".split(/\W+/))
// ["","akanka","gin","na","ma","i","rum","ki","nu"]
šとかḫとかが軒並み消えてしまっていますね。Flexsearch.jsでは語分割の前に符号化(encode)処理をすることでこれに対処することになります。例えばšをsに、ḫをhに置換してインデックス化するわけです。この場合、šakankaはsakankaでも検索できることになります。šakankaを検索語にした場合も、検索語に対しても同じ符号化を施してから検索するので同じ結果になります。[2]
ḪuburではEPSD2の翻字方針に従って置換することにしました。検索窓の脇に書かれた (j=ŋ sz=š s,=ṣ t,=ṭ 0-9=₀-₉; '=alef)というやつです。個人的にはšはcで換字するETCSL方式の方が好みなのですが、ここは本家にならうべきところでしょう。
ただし楔形文字で書かれた綴りの箇所はそのままインデックスする必要があります。Flexsearch.jsでは検索フィールドごとにEncoderやTokenizerを指定できるので、楔形文字とそれ以外ではフィールドをわけてインデックスすることにします。楔形文字では一字ごとに分割してトークン化する一方、それ以外の文は語単位に分割して前方一致でトークン化することにしました。
つまり、楔形文字で𒃻𒋗𒃡𒊏、その翻字のninda-šu-ur₃-raという行があったとき、楔形文字は"𒃻"でも"𒃡"でも"𒃻 𒊏"でもヒットするのに対し、翻字部分では"nin"や"nin šu"ではヒットしますが、"inda"ではヒットしないようにしました。
さらに、検索対象をTitle(表題)、Meaning(意味1)、Orthography(綴り)、Sense(意味2)、Equivalent(同義語)、Phrase(熟語)に分けて、別々にインデックスをつくることにしました。こうすることで検索対象を限定することができます。MeaningとSenseでふたつ意味があるのですが、これは元データで例えばninda [VESSEL] (N)とある部分のVESSELのところがMeaningで、後の項目にある"1. a measuring vessel"とある部分がSenseになっています。これは分ける必要ないかもですね……。そしてPhraseについては元データの"Phrase Data"の項目と"Lexical Associations"の項目をあわせたものなのですが、これは分割してそれぞれにインデックスしたほうがいいのかも……この辺は今後変更するかもです。
こんな感じでインデックスを作るスクリプトがこちらのファイルになります。
https://github.com/uyumyuuy/hubur/blob/main/script/make_index.js (opens new window)
できあがったインデックスファイルはこの辺においてあります。
https://github.com/uyumyuuy/hubur/tree/main/src/assets (opens new window)
当然ですがこの仕組みでなんとかなるのは欧米語だけで、日本語や中国語の文章をインデックスするには大幅な改修が必要になります。FlexSearch.jsのドキュメントにはCJKでは一文字ごとに分割するカスタムトークナイザーが紹介されていますが、これだと文字の連なりをまったく無視して検索することになるので用途はずいぶん限られるでしょう。実用的にはたぶんkuromoji.js (opens new window)のような形態素解析ライブラリを使って文節を区切るようなアプローチが求められます。
# 検索API
インデックスファイルは最終的には全部で70MB超ほどにもなってしまいました。このインデックスファイルを使った検索APIのソースコードがこちら (opens new window)になります。やっていることはかんたんで、これらのインデックスファイルを読み込んで、リクエストされた語を検索して、検索結果を返すというだけです。
ここでちょっと小細工しているのは、検索結果への重み付けです。例えば"a"という一字で検索したとき、最初に出てきてほしいのは「a [ARM] (N) (opens new window)とかa [WATER] (N) (opens new window)みたいな、aの1字だけの単語です。そこで、"Title"には200点、"Meaning"には50点、それ以外のものには10点の重みをつけることにしました。さらに、それに一致率を掛けて語ごとに積算したものをスコアにすることにしました。
例えばaという検索語に対して、a一字の語ではタイトルの一致率が100%なので200点、abなら50%で100点ということになります。他の項目でも一致があれば一致率に応じたスコアを加算して、そのスコア順に並べて検索結果としました。数字は適当に決めたのですが、なんとなくそれっぽい結果になっているのではないかと思います。
インデックスファイルが大きいので、実はこのAPIでは検索自体は10ms程度で検索できているのですが、インデックスのインポートには数秒かかっています。そんなのを毎回起動していたら応答が遅くて仕方ないですよね。実際に開発環境でvercel devで実行すると検索に毎回数秒かかるのですが、実際にデプロイしてみるとVercelは一度リクエストが来たらしばらくは起動したままにしてくれるようで二回目以降のリクエストは即座に応答してくれます。VercelのFunctionはサイズが50MBまでという制限があって[3]今回インデックスファイルが70MBあるのでだめかと思ったのですが、どうもデプロイ時に圧縮したファイルサイズで計算されるようで、このAPIでは十数MB程度の換算になっていました。Vercel神すぎる。
競合に比べるとこれはかなり大きな値です。
# UI
UIはいつもの通りVueとBuefyで作ります。プロトタイプはVue3を使ってみたのですが、BuefyはまだVue3に対応してなかったのでVue2で作り直しました。あんまり特筆すべきところはないですね。
検索は文字の入力と同時に自動的に検索結果を表示するようにしています。実際使ってみるとインクリメンタルサーチの恩恵はあんまりない気がするので検索ボタンを作ったほうがいいのかなとも思ったのですが、上で書いたように検索APIの最初の呼び出しに時間がかかることを考えるとこのままでいいかな……とも思っています。
そうそう、検索結果のハイライトにはmark.js (opens new window)を使っています。使い方はかんたんでらくちんなのですが、DOMを直接書き換える仕組みになっているためそれなりに実行時間がかかります。インクリメンタルサーチで頻繁に検索結果が更新されるのとは相性が悪いので、mark.jsのハイライトは検索結果の語ごとに分割して少しずつ実行させるようにしています。
# おわり
記事の日付は書き始めた2/12なんだけど、今は2/23だったり。一週間でつくったアプリの説明に二週間ちかくかかってしまった……。しかも使い方じゃなくて作り方の説明になってしまったぞ。使い方の記事はまた別に書いたほうがよさそうです。